java 反射
使用Java反射机制可以在运行时期检查Java类的信息,
检查Java类的信息往往是你在使用Java反射机制的时候所做的第一件事情,
通过获取类的信息你可以获取以下相关的内容:
- Class对象
- 类名
- 修饰符
- 包信息
- 父类
- 实现的接口
- 构造器
- 方法
- 变量
- 注解
使用Java反射机制可以在运行时期检查Java类的信息,
检查Java类的信息往往是你在使用Java反射机制的时候所做的第一件事情,
通过获取类的信息你可以获取以下相关的内容:
URI是下面的这样的形式
各部分标示的意思如下
| 字符串 | 用途 |
|---|---|
| http | 协议类型 |
| user:pass | 登录服务器的用户名和密码 |
| www.example.jp | 服务器地址,还可以用ipv6的标示的表示形式[0:0:0:0:0:0:0:1] |
| 80 | 端口号 |
| index.html | 带层次的文件路径 |
| uid=1 | 查询字符串 |
| ch1 | 片段标示符,锚 |
| 注解名 | 参数 | 放置位置 | 作用 | 近义词 / 来源 |
|---|---|---|---|---|
| @Required | setter方法 | 强调这个bean的该属性必须被注入 | ||
| @Autowired | required | 方法,构造器,属性 | 强调该属性ByType自动注入 | @Resource,@Inject |
| @Qualifier | 属性,构造器参数,方法参数 | 和@Autowire配合使用,当ByType冲突时候,使用ByName | ||
| @Primary | 方法,构造器,属性 | 当@Autowired ByType冲突的时候,自动选择有该注解的对象 | ||
| @Resource | name | setter方法,属性 | 同@Autowired | @Autowired,@Inject |
| @PostConstruct | 方法 | 强调该方法, 会在实例化之后自动调用 | ||
| @PreDestroy | 方法 | 强调该方法, 会在销毁之前自动调用 | ||
| @Component | 更加一般会的组件, 不确定该组件作用的时候,使用这个组件 | |||
| @Service | bane | 类 | 表示服务层 | |
| @Repository | 类 | 表示数据处理层 | ||
| @ComponentScan | basePackages, includeFilters, excludeFilters | 类 | 自动发现组件 | |
| @Bean | name, initMethod, destroyMethod | 特定方法 | 生成一个bean定义 | |
| @Description | 方法 | 和@Bean一起配合使用,指定bean的描述 | ||
| @Repository | name | 类 | ||
| @Controller | name | 类 | ||
| @Scope | name, proxyMode | 类 | 表示bean的scope域 | |
| @Inject | 方法,构造器,属性 | 强调该属性ByType自动注入 | @Autowire / JSR-330 | |
| @Named | 更加一般会的组件, 不确定该组件作用的时候,使用这个组件 | @Component / JSR-330 | ||
| @Configuration | 类 | 和标签很像,最好和@Bean搭配使用,可以解决内部依赖问题 | ||
| @Import | 类 | 和@Configuration搭配使用 | ||
| @PropertySource | 类 | 注入属性资源 |
前两天学RMI的时候,看java core上说有一个简易的HTTP服务器,只有一个类文件。就像去瞧瞧,结果发现这个类里面有20+个内部类和接口。看了源代码之后,对http服务器的理解也更加深入了。源代码
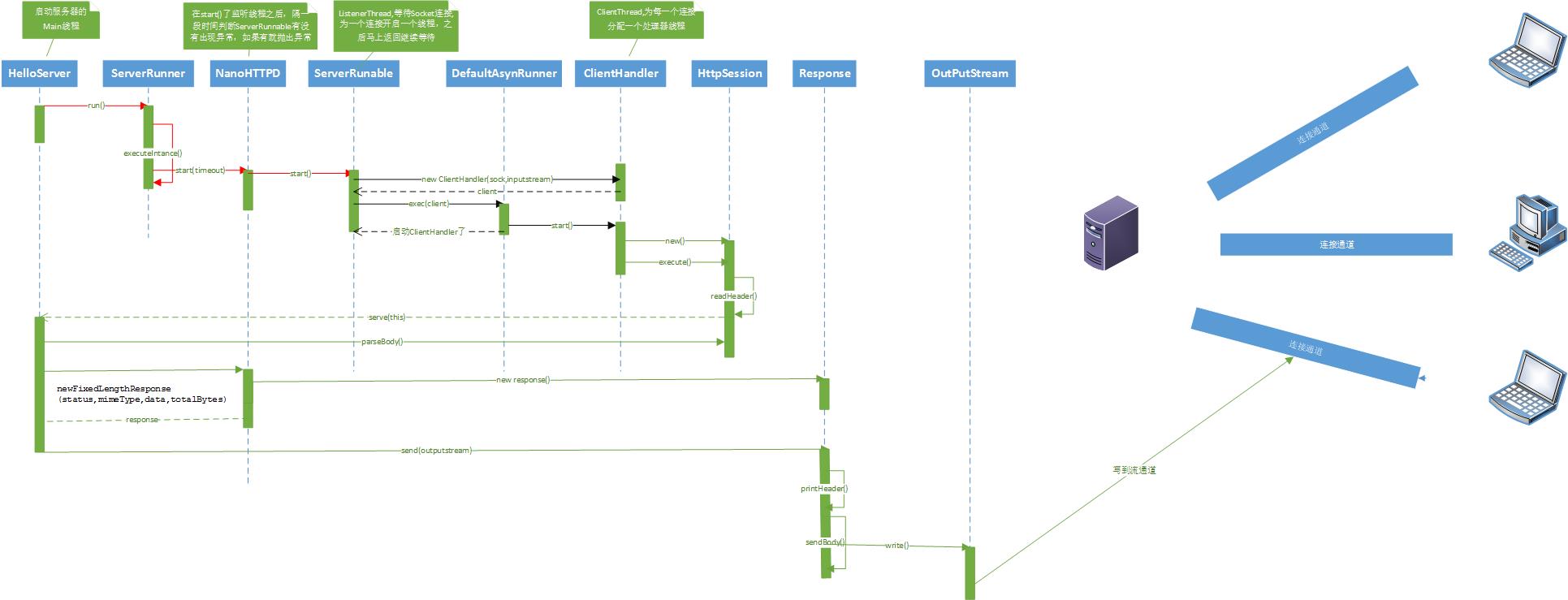
图上3中不同颜色的箭头,分别代表三种线程。>
Spring最为最强大的java 企业级开发框架,大约3年前有接触过,但是学的不深,读研的日子没有多少时间去学习这个框架,现在找实习就要用并且之前的学的是Spring 3的内容,现在都Spring 4, Servlt 3.0了变化好大,有必要重新系统的学习一边,从看官方文档开始。spring framework
Spring的核心模块包括:spring‐core , spring‐beans , spring‐context , spring‐context‐support , andspring‐expression modules.
spring‐core,spring‐beans :Beans和Core提供了最基本的DI功能
spring‐context: Context提供了在应用程序中访问对象的方式,并且在Beans和Core的基础上提供了,国际化,事件传播,资源加载的功能,同时也支持EJB,JMX等JavaEE特征,其中最重要的ApplicationContext>接口
spring‐context‐support:提供了整合第三方类库到Spring Context中,例如:(EhCache, Guava, JCache), 邮件 (JavaMail), 调度 (CommonJ, Quartz),和模板引擎(FreeMarker, JasperReports, Velocity).
spring‐expression:spring的表达式语言,扩展自 JSP规范里面的EL表达式,提供了在运行时查询或者访问对象属性值的功能,同时还支持投影,选择和聚合功能
HashMap的原理:
HashMap基于Hash算法,通过put(key,value)存储,get(key)来获取。当传入key时,HashMap会根据hash(K key)计算出hash值,根据hash值将value保存在数组里。
当计算出的hash值相同时使用链表或者红黑树来解决Hash冲突,HashMap的做法是用链表和红黑树存储相同hash值的value。当Hash冲突的个数比较少时,使用链表,否则使用红黑树。这样做的好处是,最坏的情况下即所有的key都Hash冲突,采用链表的话查找时间为O(n),而采用红黑树为O(lgn)。
java里面还有一些方法定义了没有实现,不知道会不会在1.9里面加入一些新功能
以前一直听说ArrayList底层通过数组实现,没有去阅读过源代码,为了知其然也知其所以然,开始啃源代码,ArrayList的源代码其实蛮简单的,容易理解,
ArrayList是按照插入顺序放入其内部的ElementData数组中的,元素也是可以重复放入 ,他的查询操作是直接通过数组下标的形式实现,效率高,但是删除和插入操作效率较低,需要大量移动元素。并且不是线程安全的,因为add,remove的操作都不是在原子步内进行的,单一个线程改变了size值后不会马上对另外一个线程感知。
使用ArrayList的注意事项:
默认数组大小10,每次扩容1.5倍
subList()方法返回的是一个虚拟的List视图,所有的add,remove操作都是在原来集合上,
clone()是浅拷贝
toArray()是深拷贝
循环遍历过程中如果要删除元素,请使用Iterator迭代器的remove()方法删除元素。
1.8新增了forEach()方法和Spliterator,可以接受lambda表达式
学了挺久java的了,但是发现对java里面的集合类没有达到融汇贯通的地步,之前都只是看别人的Blog,用一些常用的集合类,慢慢发现如果想再上一个台阶必须要自己去看源代码,自己去分析理解。
网上流传的集合框架图基本上都来自Core java这本书里面的集合类介绍,结合自己的理解,自己再画了一次。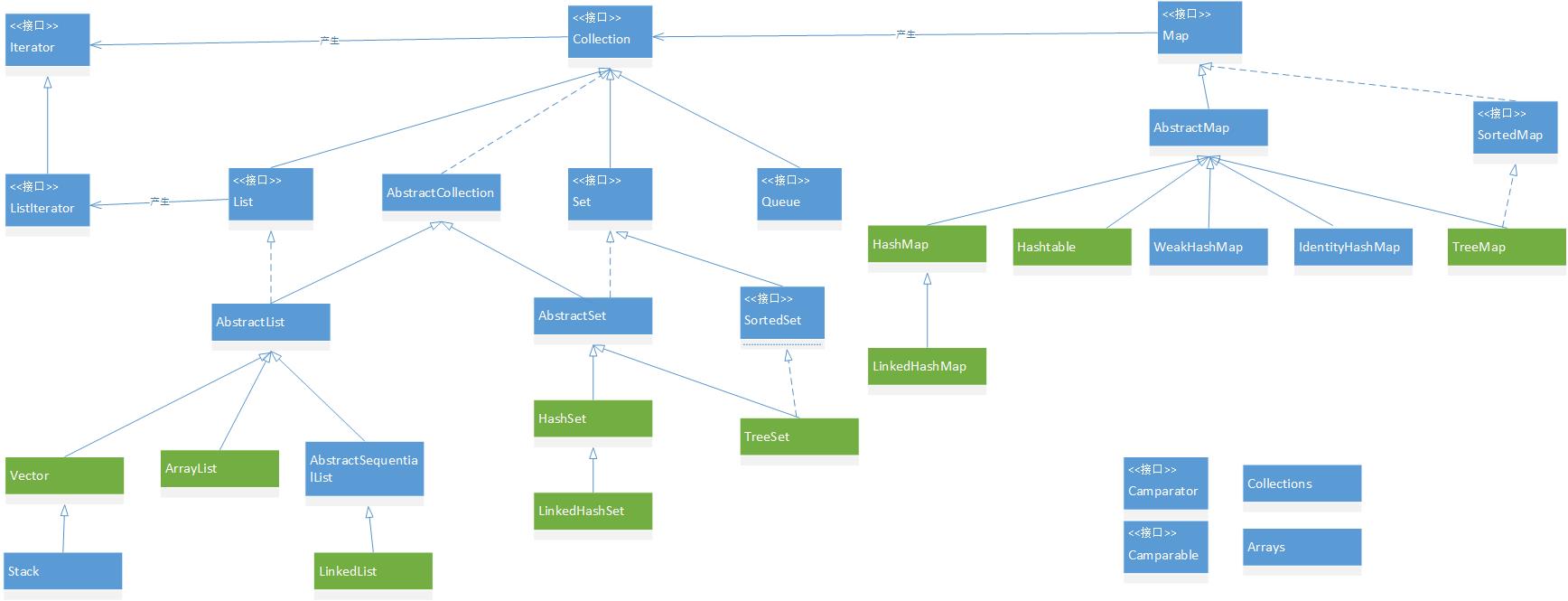
最近找实习,被问到了不少问题,来记录一下,第一次面试面的腾讯,先从腾讯说起吧
由于是第一次电面,当时4点过,我在外面吃饭,接着电话找了一个角落开始聊了
先是自我介绍,巴拉巴拉
然后问了我的研究方向,我简单的介绍了一个之后,越问越深,你的研究方向里面有哪些算法啊,介绍一下啊……
然后问了数据库的三大范式
然后问了一道算法,关于爬楼梯的:一次只能爬1级和2级台阶,问到第N 级台阶有多少种爬法,这题还好,以前在了leetcode上刷过,属于简单类型,当时想了一下就答上来了。
然后问了操作系统怎么做内存管理,程序是怎么被转入内存的,怎么切换的。我简单的说了一下,说的不详细也就这样过去了。这段时间一直忙着写论文,根本没复习过好嘛。
然后问了设计模型的单例模式怎么实现的,我回答饿汉和懒汉,然后简单的解释了一下。后来回来百度才发现有5中实现方式…..
然后问了java中hashmap 和hashtable的区别,这个比较好说。
然后问了TCP/IP 三次握手,四次挥手,为什么要3次,2次行不行。这是老问题了。
然后….想不起来了。