概述
首先tair是一个的Key-Value结构分布式存储系统,既可以做高速缓存,也可以做持久化存储。分布式系统一般来说是一个集群,而在Tair的集群中主要存在如下几个模块:
ConfigServer
一个集群中包含2台configserver,两台configserver互为主备。
- 维护和dataserver之间的心跳获得集群中存活可用的dataserver
- 根据存活的dataserver 构建数据在集群中的分布信息(对照表)
- 对client提供分部信息(对照表)的查询
- 当dataserver挂掉,或者新添加dataserver的时候,调度各个dataserver完成数据的迁移,复制
DataServer
真正存放数据的地方
- 提供数据存储服务,接受client端的put/get/remove操作。
- 执行数据迁移复制
InvalidServer
InvalidServer是一个可选模块,
- 接收来自client的invalid/hide请求,对属于同一组的集群(双机房独立集群部署方式)做delete/hide操作,保证同一组集群的一致。
Client
Tair提供出来的SDK
- 在应用端提供访问Tair集群的接口。
- 和ConfigServer通信,更新并缓存数据分布表和invalidserver地址等。
- LocalCache,避免过热数据访问影响tair集群服务。
在启动时,Client会根据本地的配置文件与ConfigServer通信。Client从Config Servcer处获得可用的DataServer地址,然后Client从这些DataServer获取真正的数据。
基本概念
集群
| 集群 | 概述 | 优点 | 缺点 |
|---|---|---|---|
| 双机房单集群单份(Dss) | 一个Tiar实例部署在两个机房中,被单个配置服务器管理,逻辑上为单集群,数据存储份数为1 | 1. 服务器存在于双机房,任一机房宕机保持可用。 2. 单份数据,无论应用在哪个机房,看到的都是同一个数据。 |
1. 应用服务器会跨机房访问。 2. 当一边机房出现故障时,tair中的数据会丢失 |
| 双机房单集群双份(Dsd) | 一个Tair实例部署在2个机房中,数据保存2份,并且同一数据的2个备份不会放在同一个数据服务器上 | 1. 数据存放两份,数据安全性有一定保障。但由于存储引擎是mdb,数据存放在内存中,无法绝对保证数据不丢失。 2. 当一边机房故障时,另外一边机房依然可以服务,并且数据不丢失。 |
如果机房间网络出现异常情况,依然有较小几率丢失数据。 |
| 双机房独立集群(Dds) | 在两个机房中同时部署2个独立的集群,这两个集群直接没有直接关系。一般作为缓存使用,Tair不保证数据的一致性. 通过一个InvalidServer来保障同一个key在两个机房是一致的 | 1. 每个机房拥有独立Tair集群,应用在哪个机房就访问相同机房的Tair集群,不会出现跨机房调用和流量。 | 1. 后端必须要有数据源,也就是这种部署方式下,Tair必然是当作传统意义上的cache存在的。因为Tair mdb集群之间本身不会做数据同步,多集群间一致性保证依赖于后端数据源,如DB。 2. 当后端数据源数据发生更新后,业务不能直接把数据put到Tair,而是先需要调用invalid接口来失效这些对等集群中的数据 |
| 双机房主备集群(Ddsm) | 这种部署方式中,存在一个主集群和一个备份集群,分别在两个机房中。数据同步由主集群透明完成。 | 1. 数据安全和服务可用性高。 2. 用户调用方便,无需考虑多集群间数据一致性的问题。 |
引擎
| 引擎 | 应用场景 | |
|---|---|---|
| mdb | 缓存,容量小,读写qps高 | 支持分层key,mdb特别注意部署方式(Dss,Dds) |
| rdb | 缓存,容量小,读写qps高 | 比mdb的存储结构更加丰富(list/map/set/zset) |
| ldb | 持久化,读写qps高 | 成本比mdb,rdb高,支持范围查找(少用) |
集群与引擎的对照关系
| 双机房单集群单份 | 双机房单集群双份 | 双机房独立集群 | 双机房主备集群 | |
|---|---|---|---|---|
| mdb | √ | √ | √ | |
| rdb | √ | |||
| ldb | √ | √ |
其他基础概念
| 基础概念 | 解释 |
|---|---|
| namespace | 又称area,隔离多个应用,各个namespace对应的应用中的数据是相互隔离的 |
| quota | 对应了每个namespace储存区的大小限制,超过配额后数据将面临最近最少使用(LRU)的淘汰 |
| expireTime | 是指数据的过期时间,当超过过期时间之后,数据将对应用不可见,这个设置同样影响到应用的命中率和资源利用率 |
| version | Tair中存储的每个数据都有版本号,版本号在每次更新后都会递增 |
| delete and invalid | 删除仅作用于一个机房数据,而失效针对多个机房。失效操作由专门的失效服务器处理,它不保证数据 立即被删除,但是保证不会被获取到 |
| LocalCache | 在客户端的cache,为了减轻dataserver负担,使用了net.sf.ehcache |
分布式一致性hash
若tair采用普通哈希即让key对机器数count取模决定key存放的机器,但当某台机器故障或增加机器时count发生变化,则原来key对应的机器发生变化,因此需要移动大量的数据。目前为了使移动的数据少一点,主要采用一致性hash算法来解决问题。在这里Tair使用改进的一致性hash算法来解决这个问题:
设有一个有限域(0-2^32)个整数,将其首尾相连形成一个环,如下图所示。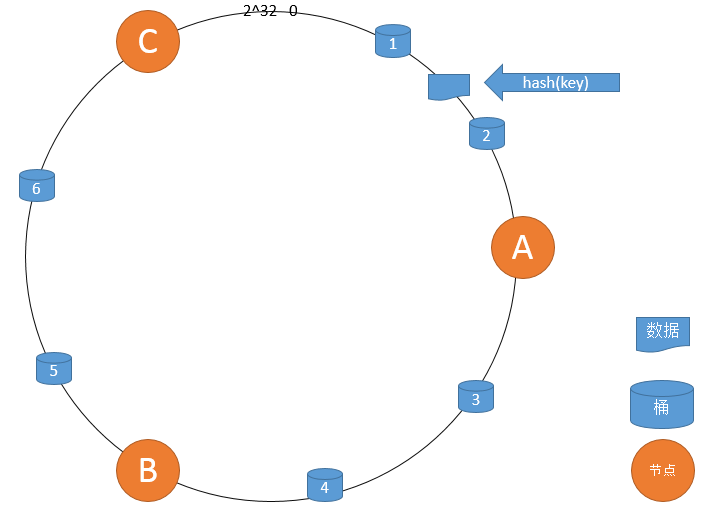
一致性哈希算法大致流程如下:
- 将dataserver根据hash函数映射到环上。
- 将bucket根据hash函数映射到换上;从bucket在环的位置开始顺时针找到第一个桶,这就是该桶所在的dataserver。
- 据key根据hash函数映射到环上,从key在环的位置开始顺时针找到第一个桶,这就是key存放的桶。
- 当某台机器坏掉时,key对应的桶映射不会变;类似2,沿着桶顺时针找到下一台机器,这就是存放该桶所在的dataserver
- 当增加dataserver时,将该dataserver与前一台dataserver(逆时针)之间的bucket存储在新增dataserver上并从原来dataserver上移除。
显然采用这种方法当机器数目发生变化时只需移动少量的数据桶。以上纯属yy,参考自:http://www.atatech.org/articles/45240,ATA上讲Tair分布式一致性hash的就这一个。如有错误,请指正。
创建对照表
对照表
Tair使用改进后的一致性hash算法来确保数据在数据服务器上趋于均匀分布,同时获取良好的可扩展性。Tair将数据按bucket为单位,存放在存储节点上,每一个节点可以存储多个bucket。对于每一个bucket而言,可能会存在多个备份。若在多备份的情况下,其中一个bucket称为master bucket,其他的称为slave bucket。Tair客户端会从configserver获取到一张表,该表记录了每一个bucket存储的节点的地址。这张表称之为对照表,如下表所示。
| Bucket Id | DataServer Ip |
|---|---|
| 1 | 192.168.0.1 |
| 2 | 192.168.0.2 |
| 3 | 192.168.0.1 |
| 4 | 192.168.0.2 |
| 5 | 192.168.0.1 |
| 6 | 192.168.0.2 |
简单的说,Tair Client 根据要put/get/remove 的key值做hash 映射到对应的bucket id ,然后根据对照表找到bucket id 对应的 dataserver ,然后和对应的dataserver进行数据交换。在这个过程中bucket的数量是固定的,也就是说key – bucket 之间的映射是固定的。 但是bucket – dataserver之间的映射却可能会发生变化:扩容,缩容,dataserver宕机等,因此需要在存活的dataserver数量发生变化的时候重建对照表,而且这个重建的过程必须对client透明。下面简单分析一下对照表的重建过程,和bucket数据迁移过程。
对照表重建
这里先忽略对照表的初始化创建过程,假设现在有一张对照表如下:
| hash_table | 1 | 2 | 3 | 4 | 5 | m_hash_table | 1 | 2 | 3 | 4 | 5 | d_hash_table | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | D | D | C | B | A | D | D | C | B | A | D | D | C | B | A | ||
| 2 | C | C | C | D | B | C | C | C | D | B | C | C | C | D | B | ||
| 3 | B | B | A | C | D | B | B | A | C | D | B | B | A | C | D |
其中:1,2,3,4,5表示有5个bucket。 1,2,3表示每一个bucket,冗余了三份数据,第一行的数据是master bucket,其他行是 salve bucket。A,B,C,D表示有4台dataserver。比如说hash_table表第一行第一列的D 表示:bucket 1作为master bucket 存放在dataserver D上。
通常有三张对照表:hash_table , m_hash_table, d_hash_table.通常情况下,这些对照表的内容相同的。只有在对照表重建后,并且有限的时间内,这些表内容不同。当重建对照表后,系统会触发数据迁移工作。待数据迁移完成后,这3张对照表内容就相同了。也就是说,只有在数据迁移过程中,对照表的内容才会不同。
对照表创建后,configserver会将hash_table表发送给Client,Clietn通过这个对照表读写数据,不至于在对照表重建过程中,无法提供服务。Configserver会将m_hash_table和d_hash_table发送到dataserver, dataserver通过这两个表来确定2件事:1)自己负责存储的bucket id;2)确定迁移的bucket id以及迁移的目标机器。
假设现在Dataserver D挂了,ConfigServer通过心跳包检测出来了,现在需要重建对照表。对照表的重建可以有两种策略:负载均衡有限,位置安全优先。
负载均衡优先:
在该策略下,构建出的对照表期望达到的效果——使得每一个节点分配的bucket数量尽可能的均衡。
1: 根据当前m_hash_table表,统计出每一个alive节点上存储的bucket数量
| alive dataserver | 目前存储的bucket数量 |
|---|---|
| A | 2 |
| B | 4 |
| C | 5 |
2: 根据 1) 中生成的map,得到下表,即对于hold相同数量bucket的节点存放在同一列表里
| 存储bucket的数量 | 存储这些数量bucket的 dataserver |
|---|---|
| 2 | {A} |
| 4 | {B} |
| 5 | {C} |
这里咋一看就是把1)中的表反过来了,其实不然,如果1)中的表还有一个E=2,那么2)中的表就是 2 = {A,E};
3: 给每一个节点分配存储bucket的数量。
这一步只是确定每一个节点上可以储存多少个bucket,而不确定到底存储哪一些bucket。对于不同的构建对照表策略,这一步骤是不同的。
在负载均衡策略下,这一步的目的就是让各个bucket尽量平均分配到各个alive dataserver,同时也要保证master bucket 也尽可能平均分配在每一个dataserver上,最后得到每一个dataserver最终要存储的bucket 总数。这里说的比较简单,详细怎么分配,可以参考:http://www.atatech.org/article/detail/6365/418。
4: 计算每一个节点预期可存储bucket的数量;
有了1) ~ 3)步的数据,现在可以计算每一个节点还可以存储的bucket的数量。
5: 快速创建对照表。在这个步骤中,系统将hash_table的第1行(master bbucket)中失效了的dataserver 替换掉。
怎么替换,替换成什么?将对应bucket的slave bucket的dataserver存储到第1行相应位置(slave bucket选为master bucket)。此时,该bucket对应的所有slave bucket所在的dataserver都可以被选择,但是需要确保:选择的dataserver上负载的master bucket不能超标(因为master bucket也需要尽可能均匀分布),并且总bucket数没有超标(因为所有的bucket都要尽可能均匀分布)。替换后,将slave bucket对应的存储节点置 null。这步骤生成的表作为新对照表的hash_table和m_hash_table对照表的内容。
6: 确定每一个bucket的存储位置。
首先,为master bucket安排存储节点。对于每一个master bucket当前所在的节点X,检查X节点是否满足要求。若不满足要求,则在该bucket的所有slave bucket中选择一个bucket,将该bucket作为master bucket(这里有可能选择不到,即时存在slave bucket,也无法选择。因为,要保证该slave bucket所在的dataserver上的总master bucket的数量不要超过一个值);若没有找到,则需要在alive的节点列表中,选择一个合适的节点S。将S节点作为这个master bucket的存储节点。更新统计数据。(这一步和第五步快速创建对照表似乎有重复地方,为了和后面的更新slave bucket做一个对比,在这里啰嗦一点)。以之前的表为例,其中Dataserver D 宕机了,重建的的hash_table和m_hash_table如下表:
| hash_table | 1 | 2 | 3 | 4 | 5 | m_hash_table | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | C | B | C | B | A | C | B | C | B | A | |
| 2 | C | B | C | B | |||||||
| 3 | B | A | C | B | A | C |
其次,为slave bucket安排存储节点。具体步骤为,首先检查bucket当前的存储节点是否满足要求(若该节点down掉了,显然不满足要求了)。若不满足要求,为其选择一个合适的节点,将该节点作为bucket的存储节点。更新统计数据。这个步骤生成的对照表,作为d_hash_table的内容。
| d_hash_table | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| C | B | C | B | A | |
| A | C | C | B | B | |
| B | A | A | C | C |
目前看来:d_hash_table中各个dataserver的对应的bucket和master bucket 分配表比较均匀如下图所示:
| dataserver | 总的bucket数量 | master bucket数量 |
|---|---|---|
| A | 5 | 1(和别的dataserver相差1,是在所难免的) |
| B | B | 2 |
| C | 5 | 2 |
bucket分配到dataserver上满足的规则大致如下:
- master bucket必须均匀的分布在各个dataserver上
- 总的bucket 也必须均匀的分布在各个dataserver上
- 在满足以上两个条件的基础上,slave bucket 升级为 master bucket。
7: 对照表同步
首先,configserver会将d_hash_table(不出意外,这就是最新的对照表)的内容保存到本地磁盘上。
其次,根据配置信息(是否允许数据迁移,是否允许数据丢失)。若无需数据迁移,那么用d_hash_table替换m_hash_table, hash_table。若需要数据迁移,统计哪些节点需要数据迁移。并且,将m_hash_table, hash_table保存在本地磁盘。最后,将对照表同步到备configserver上。
经过上述7个步骤,对照表就创建完成了。若存在数据迁移,这3个对照表内容是不同的。随着迁移的完成,3张对照表内容会变成相同的。
数据迁移
当可用dataserver发生变化后,configserver会重建对照表。每次创建对照表会输出3张表,将m_hash_table(描述当前 bucket分布的对照表),和d_hash_table(描述迁移完成后的bucket分布的对照表)通过心跳机制发给每一个dataserver节点。dataserver节点在收到对照表后,会对对照表的版本作检查。若检测到心跳信息中的对照表版本大于本地保存的对照表版本数(对照表版本数是依次递增的), 会启动一个线程,更新对照表,并完成数据迁移工作。
master bucket所在的dataserver负责迁移数据,根据这两张对照表,它可以判断出自己需要迁移的bucket,以及迁往何处。例如对于第一个bucket :由 C 负责将数据迁移到 A。第二个bucket:由B 负责迁移到 A….
以第一个bucket为例:dataserver A 启动一个后台线程来完成bucket的迁移。迁移过程中,dataserver A需要继续对外提供读写服务。对于读操作而言,返回key对应的value就行,对于写操作而言,A 会检查key对应的bucket是否迁移完毕,如果已经迁移直接返回put/delete的返回码就行,如果没有迁移完毕
dataserver节点通过一个后台线程,来完成bucket的迁移任务。迁移数据的过程中,存储节点需要继续对外提供读写服务。对于读操作而言,节点根据请求的key, 到存储节点中读取数据并返回给应用。对写操作( 包括write, delete等),存储节点会检查key对应的bucket是否已经迁移完毕(即该bucket迁移到了其他节点上了),若已迁移,则直接返回用户一个返回码(表示当前写操作没有成功,为什么??)。当bucket正在迁移,并且没有结束的时候,写操作将数据写入存储引擎,并且将将日志写入磁盘。等待迁移完成之后,通过迁移日志,目的dataserver回放日志,从而保证了一致性。 当数据完成迁移之后,A 通知config server 第一个bucket已经迁移完成。
Cache 热点问题
某些高峰时段,会大量请求同一个Key(可能对应应用的某个促销商品、热点新闻、热点评论等),根据key的hash,所有读请求都将落到同一个server上,该机器的负载就会严重加剧。解决方法是:
- 搭建一个备用集群,写的时候双写,然后随机双读。土办法,效率太低。
- 服务端做热点统计,同时通知客户端使用Local-cache逻辑:即在data-server上面运行热点统计逻辑,对每个到达的读请求,提取出key进行统计,并计算出当前请求中的热点key,同时当客户端访问的正好是热key,则向客户端回一个热点反馈feedback包。客户端收到feedback包之后,就将携带的hot-key写入客户端local-cache,同时拒绝非热key写入local-cache。
具体热点key统计方法:http://www.atatech.org/articles/39329
缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就去数据库中查找。如果key对应的value是一定不存在的,并且对该key并发请求量很大,就会对后端系统造成很大压力。
解决方法:对查询结果为空的情况也进行缓存,缓存时间设置短一点。
Tair分布式锁,原子操作
很多情况下,更新数据是先get(key),修改get回来的value,然后put回dataserver。
如果有多个客户端get到同一份数据,都对其修改并保存,那么先保存的修改就会被后到达的修改覆盖,从而导致数据一致性问题。
Tair中存储的每个Key-Value都有版本号,版本号在每次更新后都会递增,相应的,在Tair put接口中也有此version参数,这个参数是为了解决并发更新同一个数据而设置的,类似于乐观锁。使用步骤如下:
- get(key)。如果get(key)返回success,则进入步骤2;如果key 对应的value不存在,则进入步骤3.
- 在调用put(key,value,version)的时候将步骤1 中get(key)返回的verison重新传入put(key,value,version)方法。dataserver根据version是否匹配,返回client是否put成功。
- 步骤1中get(key)对应的value不存在,则新put数据。此时传入的version一定不能不是0和1(其他任何值都可以)。 因为传入0,tair会认为强制覆盖;而传入1,第一个client写入会成功后当前version=1,第二个client写入的时候发现当前写入的数据的version和当前version一样,造成数据的覆盖。
下面是一个客户端多个线程并发计数的例子:
其他
Tair文档:http://code.taobao.org/p/tair/wiki/index/
Tair源码分析2:http://www.atatech.org/article/detail/6365/418
Tair源码分析3:http://www.atatech.org/article/detail/9538/418
Tair典型使用案例:
http://www.atatech.org/articles/11131